
机器学习基础笔记(3):神经网络与深度学习 从感知机到现代架构

吴恩达:机器学习
吴恩达的机器学习课程是入门ML的经典课程,直观易懂、数学要求适中。课程涵盖监督/无监督学习、线性/逻辑回归、神经网络、SVM、聚类、降维等核心算法,以及偏差方差、正则化等实用技巧。通过编程作业(如手写数字识别、异常检测)将理论应用于实践,帮助学员快速建立完整知识框架。
为什么神经网络直到近年才真正爆发
神经网络(Neural Network)作为一种计算模型,其核心思想——用大量简单计算单元模拟生物神经元的工作方式——早在上世纪中叶便已萌芽。然而在相当长的时间里,它并未成为机器学习领域的主导力量。进入二十一世纪的第二个十年,情况发生了根本性转折。驱动这一变革的关键因素可以归纳为两条相互交织的增长曲线。
第一条曲线关乎数据规模。随着互联网的深度渗透和传感器技术的廉价化,可供模型学习的数字信息呈指数级暴涨。无论是图像、文本还是用户行为日志,海量数据的涌现为复杂模型提供了前所未有的养分。第二条曲线关乎计算能力,尤其是图形处理器(GPU)被重新发掘并用于通用并行计算。GPU 拥有成千上万个处理核心,天生适合执行神经网络中大量重复的矩阵乘法与加法运算。
当模型规模和训练数据量双双超越某个临界点后,一个显著的现象出现了:传统机器学习算法(如线性回归、支持向量机)的性能很快触及天花板,即便继续追加数据也收效甚微;而规模更大的神经网络,其表现却能持续攀升,仿佛永远看不到上限。下图中的曲线清晰地捕捉了这一规律——横轴为数据量,纵轴为模型表现,神经网络的曲线始终凌驾于传统方法之上,并且随着模型体量的膨胀而进一步上移。
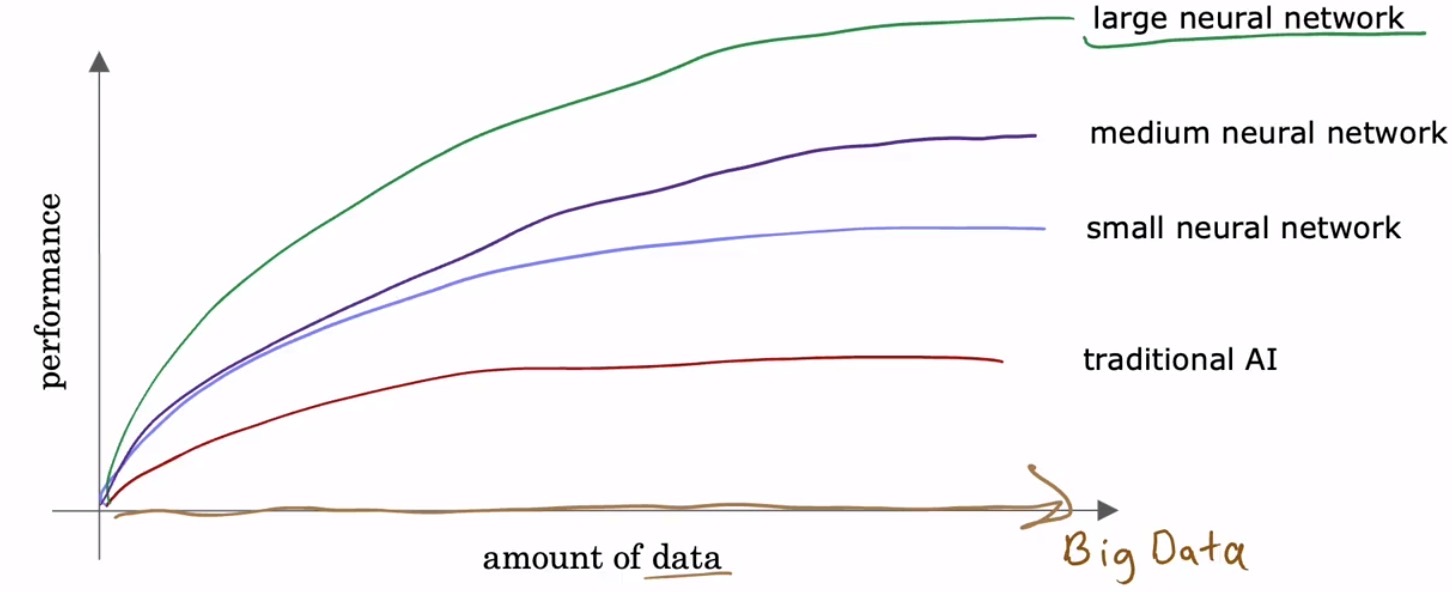
正是“大数据 + 大算力 + 大模型”的三位一体,将深度学习从学术圈的边缘推向了工业应用的中心。
从单个神经元到需求预测
神经网络的最小组成单元是神经元(Neuron)。一个神经元接受若干输入,将它们与各自的权重相乘后求和,再加上一个偏置项,最后通过一个非线性激活函数(Activation Function)输出结果。这听上去与之前讨论的逻辑回归单元几乎完全一致——事实也确实如此,逻辑回归本身就可以被视为一个仅含单个神经元的极简网络。
设想一个经典的商业场景:预测某款 T 恤在未来一周的需求量。影响销量的因素可能包括定价、运费成本、营销投入力度、面料材质等。一个单神经元模型会试图在这些输入与销量之间直接建立线性或 Sigmoid 型映射。然而真实世界的购买决策远非如此直白。消费者对价格的敏感度、对品牌品质的认知、对营销话术的接受度,这些隐含的心理变量才是决定是否下单的真正中介。
神经网络通过引入隐藏层(Hidden Layer)来显式地建模这些中间概念。输入层(Input Layer)的原始特征(价格、运费、营销支出)首先被连接到第一隐藏层的一组神经元,这些神经元可能分别对应着“可负担性感知”、“品质感知”和“品牌认知度”等抽象维度。随后,这些抽象维度的激活值(Activation)又作为输入,传递到下一层,最终汇聚到输出层(Output Layer),产生一个需求量的预测值。
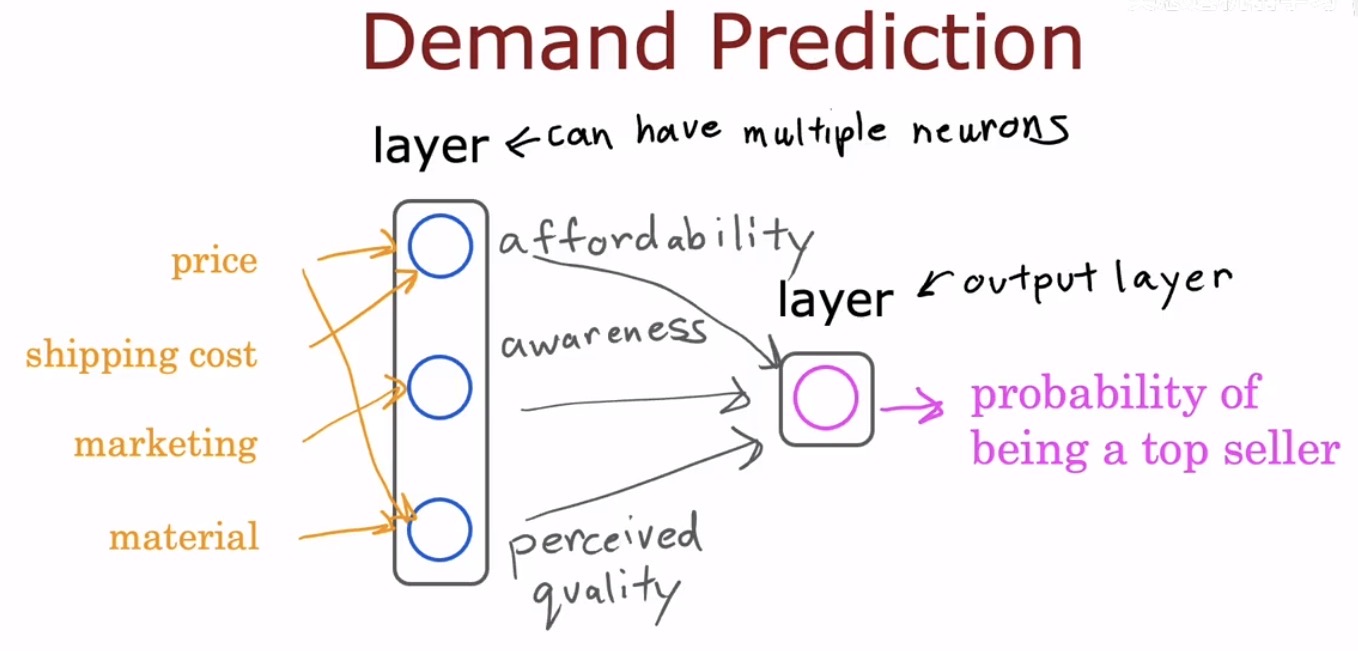
这一过程与传统特征工程有着本质区别。在特征工程中,需要依赖领域专家绞尽脑汁去设计诸如“可负担性 = 价格 / 平均收入”这样的复合特征。而神经网络中的隐藏层神经元会自动从数据中学习到这些有用表征,无需人工指定其具体含义。模型自行决定哪些中间概念对最终预测任务最有帮助,并调整相应的权重来提取它们。
图像识别领域将这种层级抽象的能力展现得淋漓尽致。输入是一张灰度图片,每一个像素的亮度值被按行依次拼接,形成一个长达数千乃至数万维的向量。这个向量被送入一个拥有多个隐藏层的深度网络。第一层神经元通常会学习到一些简单的局部特征检测器,比如对水平边缘、垂直边缘、特定角度的斜线做出响应。第二层则将这些边缘片段组合起来,形成稍复杂的结构,例如眼角的弧度、鼻梁的轮廓。随着层数加深,神经元所响应的模式愈发全局化和语义化,到最后的隐藏层,某些神经元可能已经专门对人脸的整体构型产生强烈激活。网络就这样从像素的混沌中逐层提炼出有意义的概念。
神经网络的计算图景:层与前向传播
用数学符号精确描述神经网络中的信息流动,是理解其运作机制的第一步。考虑一个具有两个隐藏层和一个输出层的简单网络。输入向量记为 $\vec{x}$。第一个隐藏层包含三个神经元,每个神经元都拥有自己的权重向量 $\vec{w}_j^{[1]}$ 和偏置 $b_j^{[1]}$(上标 $[1]$ 表示第 1 层)。该层第 $j$ 个神经元的激活值 $a_j^{[1]}$ 通过以下公式计算:
$$ a_j^{[1]} = g\left( \vec{w}_j^{[1]} \cdot \vec{x} + b_j^{[1]} \right) $$
这里 $g(\cdot)$ 代表激活函数,早期常用的是 Sigmoid 函数。三个神经元各自计算出自己的激活值,例如得到 $a_1^{[1]}=0.3$,$a_2^{[1]}=0.7$,$a_3^{[1]}=0.2$。这三个数值构成一个新的向量 $\vec{a}^{[1]}$,作为第二层的输入。
第二层仅有一个神经元,其权重向量为 $\vec{w}_1^{[2]}$,偏置为 $b_1^{[2]}$。它接收 $\vec{a}^{[1]}$,并产生该层的激活值:
$$ a_1^{[2]} = g\left( \vec{w}_1^{[2]} \cdot \vec{a}^{[1]} + b_1^{[2]} \right) $$
若这是一个二分类任务,输出层通常也采用 Sigmoid 激活,此时 $a_1^{[2]}$ 直接作为模型的最终预测概率 $\hat{y}$。可以设定一个阈值(比如 0.5),当 $\hat{y} \ge 0.5$ 时判定为正类,否则为负类。
将输入数据从第一层逐级传递,依次计算每一层的激活值,直到产生最终输出,这一完整流程被称为前向传播(Forward Propagation)。在一个稍复杂的例子中——比如识别手写数字 0 和 1——网络的规模会更大。输入是一张 20×20 像素的灰度图片,展平后得到一个 400 维的向量。这个向量流入一个含有 25 个神经元的第一隐藏层,再流经一个含有 15 个神经元的第二隐藏层,最后汇聚到一个单神经元的输出层。下图形象地展示了像素值如何逐层变换,最终浓缩为一个 0 到 1 之间的概率值。

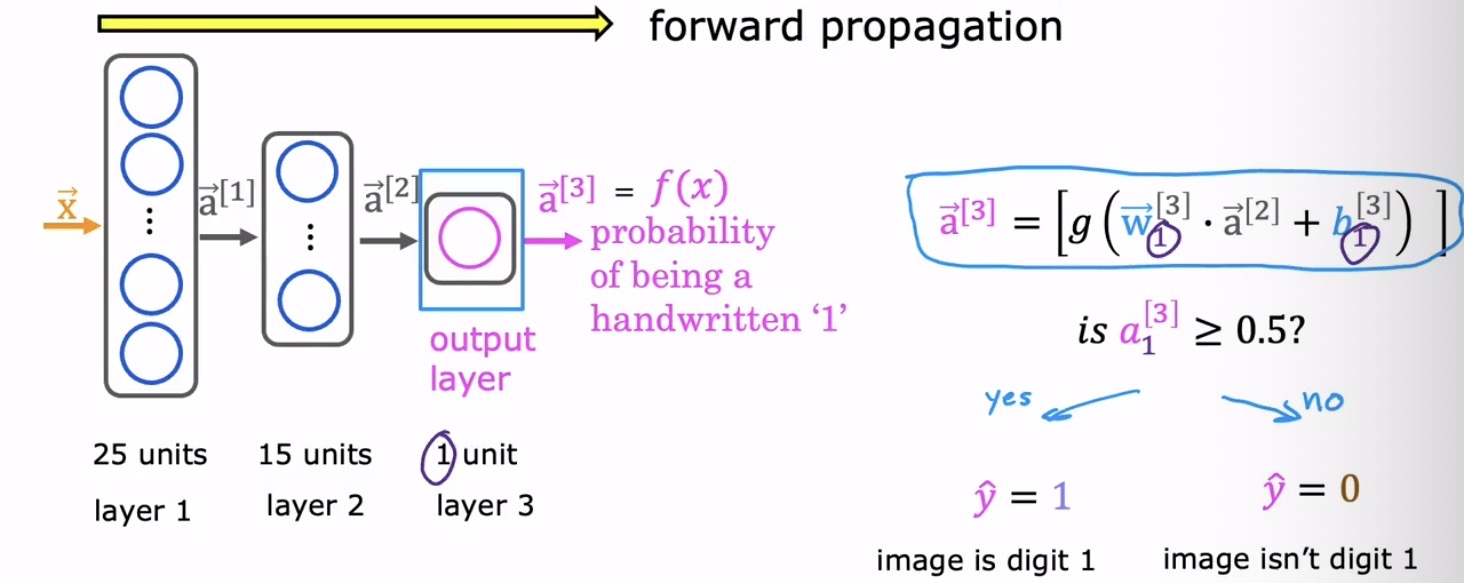
用现代深度学习框架(如 TensorFlow 或 PyTorch)搭建这样一个网络异常简洁。以 TensorFlow 的 Keras 接口为例,只需几行代码即可定义模型结构:
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(units=25, activation='sigmoid'),
Dense(units=15, activation='sigmoid'),
Dense(units=1, activation='sigmoid')
])Sequential 表示层的顺序堆叠。Dense 代表全连接层(Fully Connected Layer),即上一层的每一个神经元都与下一层的每一个神经元相连。units 指定该层神经元的个数,activation 指定激活函数类型。这里有一个历史遗留的技术细节:TensorFlow 内部的数据结构是张量(Tensor),与 NumPy 数组虽然相似,但在传递给模型进行训练或推理时,框架底层会自动处理格式转换,开发者通常无需过分操心。
深入单个全连接层的计算
为了洞悉那些简洁框架调用背后究竟发生了什么,不妨手动实现一遍全连接层的前向传播逻辑。设想一个具体情境:根据两个输入特征(如烘焙温度和烘焙时长)来预测咖啡豆的烘焙品质。网络结构为输入(2 维)→ 隐藏层(3 个神经元)→ 输出层(1 个神经元)。
对于隐藏层的每一个神经元 $j$,其计算过程为:
$$ z_j^{[1]} = \vec{w}_j^{[1]} \cdot \vec{x} + b_j^{[1]} $$ $$ a_j^{[1]} = g(z_j^{[1]}) $$
这一过程可以用 Python 函数来抽象。下面的 dense 函数接收来自上一层的激活向量 a_in、当前层的权重矩阵 W、偏置向量 b 以及激活函数 g,返回当前层的输出激活向量 a_out:
import numpy as np
def dense(a_in, W, b, g):
units = W.shape[1] # 该层神经元数量
a_out = np.zeros(units) # 初始化输出向量
for j in range(units):
w = W[:, j] # 取出第 j 个神经元的权重向量
z = np.dot(w, a_in) + b[j]
a_out[j] = g(z)
return a_out循环遍历每一个神经元,计算其线性组合 $z$,再应用激活函数,将结果填入输出数组。当层数为 3 时,units = 3,a_out 被初始化为 [0, 0, 0],循环结束后返回长度为 3 的激活向量。
有了 dense 函数,整个前向传播可以自然地表达为逐层调用的过程:
def sequential(x):
a1 = dense(x, W1, b1, sigmoid)
a2 = dense(a1, W2, b2, sigmoid)
a3 = dense(a2, W3, b3, sigmoid)
a4 = dense(a3, W4, b4, sigmoid)
return a4注意这里用大写字母 $W$ 表示矩阵,小写字母 $\vec{w}$ 或 $b$ 表示向量或标量。在实际神经网络中,一层的所有权重向量被堆叠成一个矩阵 $W$,该矩阵的第 $j$ 列正是第 $j$ 个神经元的权重向量。这样的表示法为后续的向量化实现铺平了道路。
向量化:从逐神经元循环到矩阵乘法
上述 dense 函数虽然逻辑正确,但其内部的 Python for 循环在面对大规模网络和海量数据时效率极低。向量化(Vectorization)的威力在于将循环隐式地交由高度优化的底层线性代数库(如 BLAS、cuBLAS)来执行,并且能够充分利用 GPU 的并行架构。
考虑同样的咖啡烘焙网络,输入是一个包含两个特征的样本向量 $\vec{x} = [200, 17]$。第一隐藏层有三个神经元,其权重矩阵 $W$ 的尺寸为 $2 \times 3$(两行三列),偏置向量 $\vec{b}$ 长度为 3。不使用循环的向量化计算步骤如下:
x = np.array([200, 17])
W = np.array([
[1, -3, 5],
[-2, 4, -6]
])
b = np.array([-1, 1, 2])
def dense_vectorized(a_in, W, b, g):
z = np.matmul(a_in, W) + b # 矩阵乘法与广播加法
a_out = g(z)
return a_outnp.matmul(a_in, W) 计算的是向量 $\vec{a}_ {\text{in}}$ 与矩阵 $W$ 的乘积,结果是一个长度为 3 的向量,其第 $j$ 个元素正好等于 $\vec{a}_ {\text{in}}$ 与 $W$ 第 $j$ 列的点积。这一步同时算出了所有三个神经元的线性输出 $z_j$,没有任何显式循环。再加上偏置向量 $\vec{b}$(广播机制自动将 $\vec{b}$ 逐元素加到乘积结果的对应位置),最后对整个向量应用激活函数 $g$,一气呵成。
当输入不再是单个样本,而是一个包含 $m$ 个样本的批量数据时,向量化的优势更加突出。设输入矩阵 $X$ 的形状为 $m \times 2$,每一行是一个样本的特征向量。权重矩阵 $W$ 仍为 $2 \times 3$。矩阵乘法 $Z = X W$ 的结果是一个 $m \times 3$ 的矩阵,其中第 $i$ 行正是第 $i$ 个样本在第一隐藏层的线性输出。这种批量处理方式让计算密度大增,GPU 的数千核心得以满载运转。
为了透彻理解矩阵乘法在此处的角色,可以回顾一个简单的例子:
A = np.array([[1, -1, 0.1],
[2, -2, 0.2]])
W = np.array([[3, 5, 7, 9],
[4, 6, 8, 0]])
Z = np.matmul(A, W)
# 或使用 @ 运算符: Z = A @ W矩阵 $A$ 的尺寸为 $2 \times 3$,矩阵 $W$ 的尺寸为 $3 \times 4$(此处 $W$ 需要转置理解,实际神经网络中权重矩阵的排布方式通常为 [输入特征数, 神经元数])。乘积矩阵 $Z$ 的尺寸为 $2 \times 4$,每一个元素都是 $A$ 的某一行与 $W$ 的某一列的点积。正是这种大规模的矩阵运算,构成了现代深度学习框架的计算骨干。
TensorFlow 中的模型训练全景
在熟练掌握了前向传播的数学本质后,回到 TensorFlow 这类高层框架,便可理解 model.compile 和 model.fit 背后所封装的完整训练范式。无论是最简单的逻辑回归,还是深达数十层的神经网络,监督学习的训练流程始终遵循相同的三步模板。
第一步:指定如何根据输入和参数计算输出,即定义模型结构。
对于逻辑回归,直接写出数学表达式并用代码实现:
z = np.dot(w, x) + b
f_x = 1 / (1 + np.exp(-z))对于神经网络,则使用层叠的方式定义:
model = Sequential([
Dense(units=25, activation='sigmoid'),
Dense(units=15, activation='sigmoid'),
Dense(units=1, activation='sigmoid')
])第二步:指定用于衡量模型预测与真实标签之间差异的损失函数(Loss Function)和代价函数(Cost Function)。
逻辑回归中,单个样本的损失为二元交叉熵(Binary Crossentropy):
loss = -y * np.log(f_x) - (1 - y) * np.log(1 - f_x)所有样本损失的平均值构成代价函数 $J(\vec{w}, b)$。在 TensorFlow 中,只需在编译时指明损失函数:
from tensorflow.keras.losses import BinaryCrossentropy
model.compile(loss=BinaryCrossentropy())第三步:在训练数据上通过迭代优化算法最小化代价函数。
逻辑回归采用梯度下降,显式写出参数更新:
w = w - alpha * dj_dw
b = b - alpha * dj_db神经网络的参数规模可能达到百万甚至亿级,手动为每一个参数计算梯度并不可行。框架通过自动微分和反向传播(Backpropagation)算法,高效地计算出代价函数关于每一个参数的偏导数。开发者只需调用一行代码:
model.fit(X, Y, epochs=100)这里的 epochs=100 表示整个训练数据集将被遍历 100 次。每一次完整遍历称为一个轮次(Epoch)。在每一轮次内部,数据被划分为若干小批量(Mini-batch),依次进行前向传播、损失计算、反向传播和参数更新。fit 函数将这套复杂的流程封装得极为友好,同时会在训练过程中实时输出损失值的变化,方便监控收敛情况。
激活函数的演进:为何 Sigmoid 并非万能
在神经网络早期,Sigmoid 函数 $g(z) = \frac{1}{1+e^{-z}}$ 是最为主流的激活函数选择。它平滑、可导,且能将输出天然压缩到 $(0,1)$ 区间,非常适合作为二分类输出层的激活函数。然而当网络深度增加时,Sigmoid 的固有缺陷逐渐暴露。
在反向传播过程中,梯度需要从输出层逐层向前传递。Sigmoid 函数在两端的饱和区导数趋近于零,导致梯度在回传时被逐层“稀释”,最终靠近输入层的参数几乎接收不到有效的更新信号。这一现象被称为梯度消失(Vanishing Gradient),严重阻碍了深层网络的训练。
修正线性单元(Rectified Linear Unit,简称 ReLU)的出现很大程度上解决了这一问题。其定义极尽简单:
$$ g(z) = \max(0, z) $$
当 $z > 0$ 时,导数为常数 1,梯度可以毫无衰减地向浅层传播;当 $z \le 0$ 时,输出为零,导数为零,这相当于引入了一种稀疏性,反而常常被证明对模型泛化有益。ReLU 的计算开销远小于 Sigmoid 中的指数运算,且其单侧抑制、单侧线性的特性在实践中被证明非常有效,目前已成为绝大多数隐藏层的默认激活函数选项。
另一种备选是线性激活函数 $g(z) = z$,它通常仅用于特定场景(如回归任务的输出层,因为输出需要是一个无界的连续值)。
选择激活函数的原则可以归纳如下:
- 对于二分类问题的输出层,Sigmoid 仍然是最自然的选择,因为输出可被解释为概率。
- 对于回归问题,若输出值可以取任意实数,输出层采用线性激活函数。
- 对于隐藏层,在绝大多数情况下优先考虑 ReLU。它不仅计算更快,而且能有效缓解梯度消失,让深层网络的训练成为可能。
- 对于多分类问题的输出层,则需要引入 Softmax 激活函数,后文将详述。
一个关键问题是:如果网络中所有神经元都使用线性激活函数,会发生什么?简单的数学推导表明,若干线性变换的复合仍然是线性变换。一个没有非线性激活函数的深度网络,无论堆叠多少层,其表达能力都完全等价于一个单层线性模型。激活函数的本质使命正是为网络注入非线性因素,使其能够学习输入与输出之间错综复杂的映射关系。ReLU 之所以有效,恰恰在于它在 $z=0$ 处的弯折打破了纯粹的线性。
多分类问题与 Softmax 回归
手写数字识别是一个典型的多分类任务——输入一张图片,输出 0 到 9 共十个类别中的一个。二分类的 Sigmoid 输出层在此不再适用,需要一种能够同时输出多个类别概率的机制,且所有概率之和必须为 1。
Softmax 回归是逻辑回归在多分类场景下的自然推广。假设有 $N$ 个可能的类别。对于给定的输入 $\vec{x}$,首先为每个类别 $j$ 计算一个线性得分 $z_j = \vec{w}_j \cdot \vec{x} + b_j$。随后,通过 Softmax 函数将这些得分转换为概率分布:
$$ a_j = \frac{e^{z_j}}{\sum_{k=1}^{N} e^{z_k}} = P(y = j \mid \vec{x}) $$
指数函数 $e^{z_j}$ 确保所有概率值为正,分母的求和则起到归一化作用,强制所有 $a_j$ 之和为 1。当 $N=2$ 时,Softmax 退化为 Sigmoid 函数,可见其是更一般的表达。
在多分类设定下,衡量模型表现需要用到的损失函数为稀疏类别交叉熵(Sparse Categorical Crossentropy)。对于单个样本,若其真实类别标签为 $y$,则损失定义为:
$$ \text{loss} = -\log a_y $$
这一公式的含义非常直观:模型对真实类别所赋予的概率 $a_y$ 越小,$-\log a_y$ 的值就越大,惩罚越重。训练过程会竭力推动 $a_y$ 趋近于 1,即让模型对正确类别的预测信心尽可能充足。
在 TensorFlow 中,构建一个用于 10 类手写数字识别的 Softmax 输出网络仅需对前述代码稍作修改:
model = Sequential([
Dense(units=25, activation='relu'),
Dense(units=15, activation='relu'),
Dense(units=10, activation='softmax')
])
from tensorflow.keras.losses import SparseCategoricalCrossentropy
model.compile(loss=SparseCategoricalCrossentropy())
model.fit(X, Y, epochs=100)隐藏层改用 ReLU 激活以加速训练,输出层单元数设为 10,激活函数指定为 softmax。损失函数更换为 SparseCategoricalCrossentropy,其中 Sparse 意指标签 $Y$ 是以整数形式(0, 1, 2, …, 9)给出的,而非独热编码(One-hot Encoding)向量。
Softmax 的数值稳定性改进
在计算机中实现 Softmax 时,存在一个微小但值得警惕的数值问题。当某个得分 $z_j$ 非常大时,$e^{z_j}$ 可能超出浮点数的表示上限,导致上溢。反之,若所有 $z_j$ 均为绝对值很大的负数,分母趋于零,可能引发下溢。
TensorFlow 等成熟框架在计算交叉熵损失时,提供了一个融合版本,它不在内部显式计算出完整的 Softmax 概率向量 $a_j$,而是直接将线性输出 $z_j$ 与真实标签 $y$ 代入一个数学上等价但数值更稳定的公式中。在 Keras 中,推荐的做法是将输出层的激活设为 linear,并在 compile 时指定 loss=SparseCategoricalCrossentropy(from_logits=True)。from_logits=True 告知损失函数接收的是未经 Softmax 处理的原始得分(Logits),内部会自动采用数值稳定技巧。这一细节虽不起眼,却在训练复杂模型时能有效避免 NaN 的出现。
多标签分类:一次预测多个二值属性
多分类问题假定每个样本属于且仅属于一个类别。与之并列的另一种场景是多标签分类(Multi-label Classification),此时一个样本可以同时拥有多个标签。例如,一张交通监控图像中可能同时包含小汽车、公交车和行人。模型的输出不再是一个独一的类别编号,而是一个长度等于标签总数的向量,向量中的每一个元素是一个独立的二分类结果(存在或不存在)。
网络的输出层结构因此需要调整:神经元数量等于标签种类数(例如 3 个),且每个输出神经元均采用 Sigmoid 激活函数,独立地输出该标签存在的概率。此时的损失函数通常使用二元交叉熵(Binary Crossentropy),对每一个标签单独计算损失并求和。这一范式在图像标注、推荐系统等场景中应用十分广泛。
从单神经元的逻辑回归,到多隐藏层的深度网络,再到多分类和多标签的灵活输出结构,神经网络展现出了对各类数据形态与任务需求的极强适应力。而理解这些模型背后的计算细节——无论是前向传播的矩阵乘法,还是激活函数的选择逻辑——都将为搭建、调试并优化自己的深度学习系统提供坚实的认知基础。
