
机器学习基础笔记(2):多元线性回归 从单一特征到多维空间

吴恩达:机器学习
吴恩达的机器学习课程是入门ML的经典课程,直观易懂、数学要求适中。课程涵盖监督/无监督学习、线性/逻辑回归、神经网络、SVM、聚类、降维等核心算法,以及偏差方差、正则化等实用技巧。通过编程作业(如手写数字识别、异常检测)将理论应用于实践,帮助学员快速建立完整知识框架。
多个特征的引入
之前探讨线性回归时,为了简化问题,始终假定输入只有一个特征,即房子面积这一个变量,模型可以写为 $f_{w,b}(x) = wx + b$。然而现实世界的建模问题几乎不可能如此单纯。房价的最终成交数字除了受面积影响,还与卧室数量、建造年份、所处楼层、周边学校评分等诸多因素纠缠在一起。将这些信息全部纳入考量,预测才可能具备实际参考价值。
因此,模型必须能够接纳多个输入特征。引入一套系统化的记号来管理这种复杂性变得必不可少。设特征的总数为 $n$,第 $j$ 个特征记为 $x_j$。一个包含 $n$ 个特征的训练样本不再是一个孤立的标量,而是一个由多个数值构成的向量,记作 $\vec{x}^{(i)} = [x_1^{(i)}, x_2^{(i)}, \dots, x_n^{(i)}]$,其中上标 $(i)$ 依然表示这是第 $i$ 个训练样本。例如,$x_3^{(2)}$ 就代表第二个样本中第三个特征的具体取值,可能对应着那套房子的楼层数。
下图清晰地展示了在房价预测任务中,这些符号与具体数据列之间的对应关系。表格的每一行是一个样本,每一列是一个特征,最右侧是目标值 $y$,也就是真实成交价格。
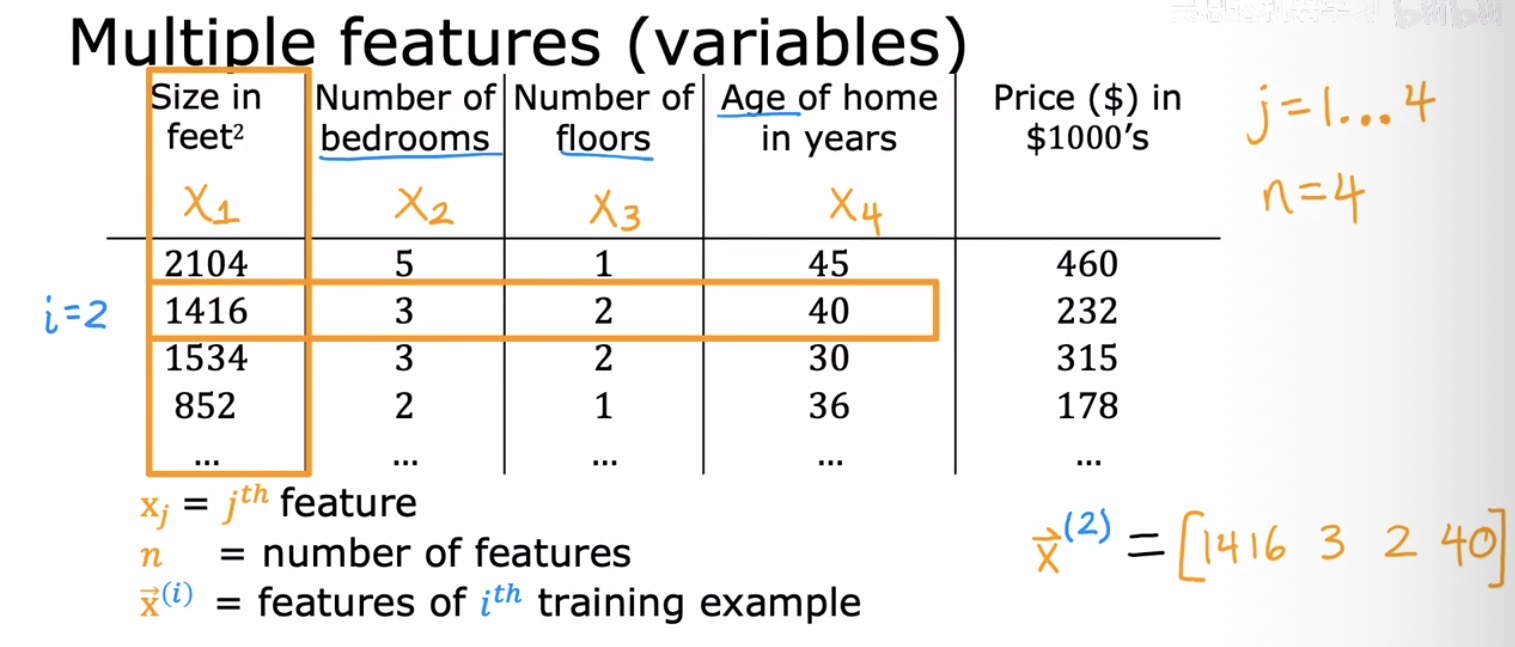
有了向量的概念,原先的单变量线性回归模型可以非常自然地扩展为多元线性回归(Multiple Linear Regression)形式:
$$ f_{\vec{w},b}(\vec{x}) = w_1 x_1 + w_2 x_2 + \dots + w_n x_n + b $$
这个表达式具有直观的解释:每一个特征 $x_j$ 都有自己专属的权重参数 $w_j$,表征该特征对最终预测值的影响力度与方向;偏置项 $b$ 则扮演基础值的角色,可以理解为当所有特征都取零时的一个基准输出。在房价例子中,$x_1$ 若是面积,$w_1$ 就是每平米单价;$x_2$ 若是卧室数量,$w_2$ 则是每增加一个卧室带来的溢价;$b$ 则可以视作即便房子面积为零也存在的某种基础成本(虽然现实中无意义,但数学上不可或缺)。
将所有权重 $w_1$ 到 $w_n$ 整合为一个向量 $\vec{w} = [w_1, w_2, \dots, w_n]$,模型便可以简洁地表示为向量内积的形式:
$$ f_{\vec{w},b}(\vec{x}) = \vec{w} \cdot \vec{x} + b $$
这里 $\vec{w} \cdot \vec{x}$ 代表两个向量的点乘运算,即对应位置元素相乘后求和。
向量化:让计算从串行变为并行
当特征数量达到成百上千,训练样本数以万计时,若用显式的 for 循环逐个累加 $w_j x_j$,计算效率将低得难以忍受。向量化(Vectorization)正是为解决这一性能瓶颈而生。它的核心思想是利用现代处理器(尤其是图形处理器 GPU)的并行计算能力,将原本需要一条条顺序执行的标量运算,打包成一条向量指令同时完成。
在实际代码实现中,通常会借助 NumPy 这类数值计算库。只需将 $\vec{w}$ 和 $\vec{x}$ 分别创建为 NumPy 数组:
w = np.array([w1, w2, ..., wn])
x = np.array([x1, x2, ..., xn])那么一次 np.dot(w, x) + b 就能瞬间得到预测值,其底层是高度优化的 C 语言和并行计算指令。相比之下,手写一个 Python for 循环去遍历索引并累加,不仅代码冗长,更致命的是每一步迭代都要在 Python 解释器中完成类型检查、函数调用等额外开销,速度差距可达数十倍甚至上百倍。当模型需要在训练过程中反复计算成千上万次预测值时,向量化带来的加速效应直接决定了整个项目是否可行。
多元线性回归的梯度下降算法也因此得以用向量化形式优雅重写。代价函数仍然是均方误差:
$$ J(\vec{w},b) = \frac{1}{2m} \sum_{i=1}^{m} \left( \vec{w} \cdot \vec{x}^{(i)} + b - y^{(i)} \right)^2 $$
参数更新的偏导数公式在形式上几乎不变,只是对 $w_j$ 的偏导需要乘以对应的特征值 $x_j^{(i)}$:
$$ \frac{\partial J}{\partial w_j} = \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} $$
$$ \frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) $$
使用向量化计算时,所有 $w_j$ 的梯度可以一次性通过矩阵运算得出,无需为每一个 $w_j$ 单独写一个循环。这种简洁和高效,使得梯度下降在面对高维特征空间时依然游刃有余。
这里顺带提及另一种求解线性回归参数的方法——正规方程(Normal Equation)。它通过直接对代价函数求导并令其为零,给出一个封闭形式的解析解。然而正规方程需要计算矩阵的逆,当特征数量 $n$ 较大时(例如超过一万),矩阵求逆的计算复杂度极高,且数值稳定性堪忧。相比之下,梯度下降及其变体对特征数量的敏感度要低得多,适用范围远为广阔,这也是梯度下降成为主流优化算法的根本原因。
特征缩放:让梯度下降的路走得更顺
当不同特征的取值范围存在数量级上的巨大差异时,梯度下降的表现会变得非常挣扎。考虑一个典型的例子:房屋面积 $x_1$ 的数值在 300 到 2000 之间浮动,而卧室数量 $x_2$ 仅在 0 到 5 之间变化。这两个特征的值域跨度相差数百倍。
这种差异对模型参数的尺度产生了直接影响。若面积对应的权重 $w_1$ 取 50,卧室数对应的权重 $w_2$ 取 0.1,模型输出才可能落在一个合理的数值区间。换言之,$x_1$ 范围大,其配套的 $w_1$ 往往较小;$x_2$ 范围小,其配套的 $w_2$ 往往较大。这在代价函数的等高线图上会体现为一个极度狭长、被挤压成椭圆形的山谷。椭圆的长轴对应着尺度较小的参数方向,短轴对应着尺度较大的参数方向。
梯度下降在如此畸形的代价函数曲面上行进时,会沿着陡峭的谷壁反复横跳,呈现出剧烈的锯齿状震荡,每前进一步都耗费大量时间在来回摆动上,而真正朝向谷底中心的进展却微乎其微。收敛过程因此变得漫长甚至停滞。
为了让梯度下降走得平稳高效,需要将所有特征缩放到相近的数值量级,使得代价函数的等高线尽可能接近一个规整的圆形。特征缩放(Feature Scaling)正是为此而设计的预处理步骤。
一种最朴素的方法是将每个特征除以其数据范围内的最大值。例如面积统一除以 2000,卧室数统一除以 5,这样所有特征值都会被压缩到 0 到 1 的区间内。
另一种常用技巧是均值归一化(Mean Normalization)。先从每个特征值中减去该特征在整个训练集上的均值 $\mu$,再除以该特征的最大值与最小值之差:
$$ x’ = \frac{x - \mu}{\max - \min} $$
经过这般处理,特征值通常会落在 $[-1, 1]$ 的范围内,且均值大致为零。
还有 Z 值标准化(Z-score Normalization),它在统计学中应用极广。公式是将减去均值后的差值除以该特征的标准差 $\sigma$:
$$ x’ = \frac{x - \mu}{\sigma} $$
经此变换后,特征的均值为 0,标准差为 1。Z 值标准化并不强行将数值限定在某个固定区间,但绝大部分数据会集中在 $[-3, 3]$ 之内。
在实践中,只要特征的值域大致落在零附近,且上下界不超过个位数级别,通常就无需再做额外缩放。但若某个特征的取值范围跨越了 $[-100, 100]$ 甚至更宽,或者与其他特征存在数量级的鸿沟,那么特征缩放几乎是保证梯度下降正常工作的必备工序。
判断收敛与选择学习率
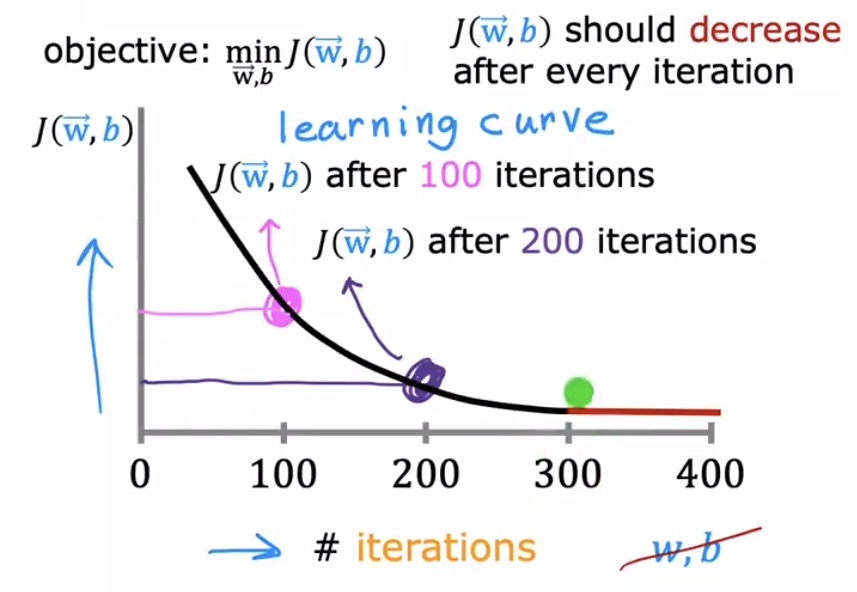
梯度下降是一个迭代过程,运行到何时才能停手?需要一种客观的手段来评判算法是否已经收敛。学习曲线(Learning Curve)提供了这一诊断视角。它以迭代次数为横轴,以每次迭代后的代价函数值 $J(\vec{w},b)$ 为纵轴,绘制出一条随训练进行而变化的曲线。
一条健康的学习曲线应当单调下降,并在迭代一定次数后趋于平坦。这条曲线至少传递出两条关键信息。其一,若曲线中途出现上扬或剧烈震荡,几乎可以断定是学习率 $\alpha$ 设置过大,导致参数在谷底附近越过最低点;当然也不排除代码实现中存在逻辑错误。其二,可以通过观察曲线走平的位置来判断大概经过多少次迭代后模型已经收敛。图中所示大约在 300 次迭代后曲线便不再有明显下降。
为了自动化判断收敛,可以设定一个极小的阈值 $\epsilon$,例如 $10^{-3}$。当一次迭代前后代价函数值的下降幅度小于 $\epsilon$ 时,便认为算法已经收敛,可以提前终止循环。
学习率 $\alpha$ 的选择本身也是一门微妙的技艺。若 $\alpha$ 过大,代价函数可能不降反升,或持续震荡无法收敛。若 $\alpha$ 过小,收敛速度将慢如蜗牛,浪费大量算力。通常的做法是从一个较小的值开始尝试(如 0.001、0.01),观察学习曲线的走势,逐步放大或缩小,直至找到一个让代价函数稳定且快速下降的合适取值。
特征工程:为数据赋予新的视角
原始数据中的特征未必是预测目标的最佳表达形式。有时,对现有特征进行组合、变换或构造,能够极大地提升模型的表现力,这一过程称为特征工程(Feature Engineering)。
仍以房价预测为例。数据表格中可能给出了每块土地的面宽 $x_1$ 和进深 $x_2$,但一个更直观、与房价关联更紧密的变量其实是土地的总面积。于是可以定义一个新的特征 $x_3 = x_1 \times x_2$,将长度和宽度这两个原始信息融合为一个更具物理含义的面积特征。模型现在同时拥有 $x_1$、$x_2$ 和 $x_3$,参数也从两个增加到三个,拟合能力得到增强。
特征工程不仅可以创造乘积项,还可以引入多项式特征。若怀疑目标值与某个特征之间存在曲线关系,比如面积对房价的边际效应递减,那么可以构造面积的平方项 $x^2$ 或立方项 $x^3$。需要格外注意的是,引入高次多项式特征后,不同特征的数值量级会进一步拉开差距,特征缩放的重要性在此刻更加凸显。例如面积原本在 300 到 2000 之间,其平方项就会达到百万量级,若不进行缩放,梯度下降将寸步难行。
逻辑回归:从连续值走向分类决策
分类问题的引入与线性回归的局限
监督学习的另一大分支是分类(Classification)。在二分类(Binary Classification)任务中,输出 $y$ 只能取两个离散值,通常记为 0 和 1,分别代表“否”与“是”两种类别。
设想一个根据肿瘤尺寸判断其是否为恶性的医疗诊断场景。如果用线性回归强行拟合,并设定一个阈值(比如 0.5)来划分类别——预测值大于 0.5 判为恶性,小于 0.5 判为良性——在某些情况下确实可行。但这种做法存在一个致命缺陷:线性回归对极端值极其敏感。若训练集中意外出现一个尺寸异常巨大的良性肿瘤样本,为了迁就这个离群点,拟合直线的斜率会被大幅度压低,整条直线变得更为平缓。这将直接导致阈值 0.5 所对应的横轴分界点向右漂移,许多原本应被正确判定为恶性的中等尺寸肿瘤因此被错误地划入良性区域。
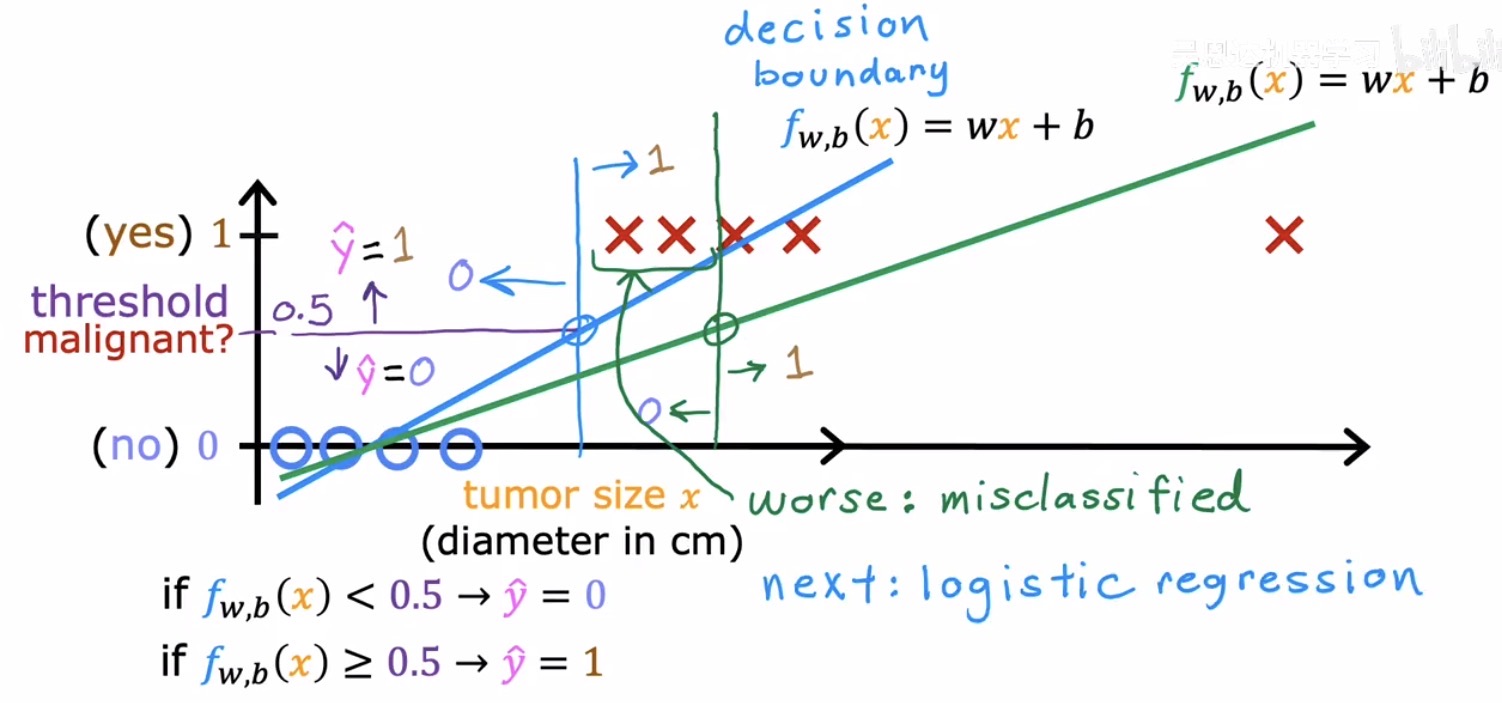
这表明,线性回归的输出是一个无界的连续值,而分类任务需要的输出是一个介于 0 和 1 之间的概率值,或直接是一个离散标签。必须寻找一种能够将任意实数输入“挤压”到 $[0,1]$ 区间内的数学工具。
Sigmoid 函数与逻辑回归模型
逻辑回归(Logistic Regression)虽然名字中含有“回归”二字,却是一种不折不扣的分类算法。它的核心构件是 Sigmoid 函数,也称逻辑函数,其数学形式为:
$$ g(z) = \frac{1}{1 + e^{-z}} $$
这个函数的图像是一条优雅的 S 形曲线。当 $z$ 趋向正无穷时,分母趋近于 1,函数值趋近于 1;当 $z$ 趋向负无穷时,分母趋近于正无穷,函数值趋近于 0;当 $z=0$ 时,函数值恰好为 0.5。
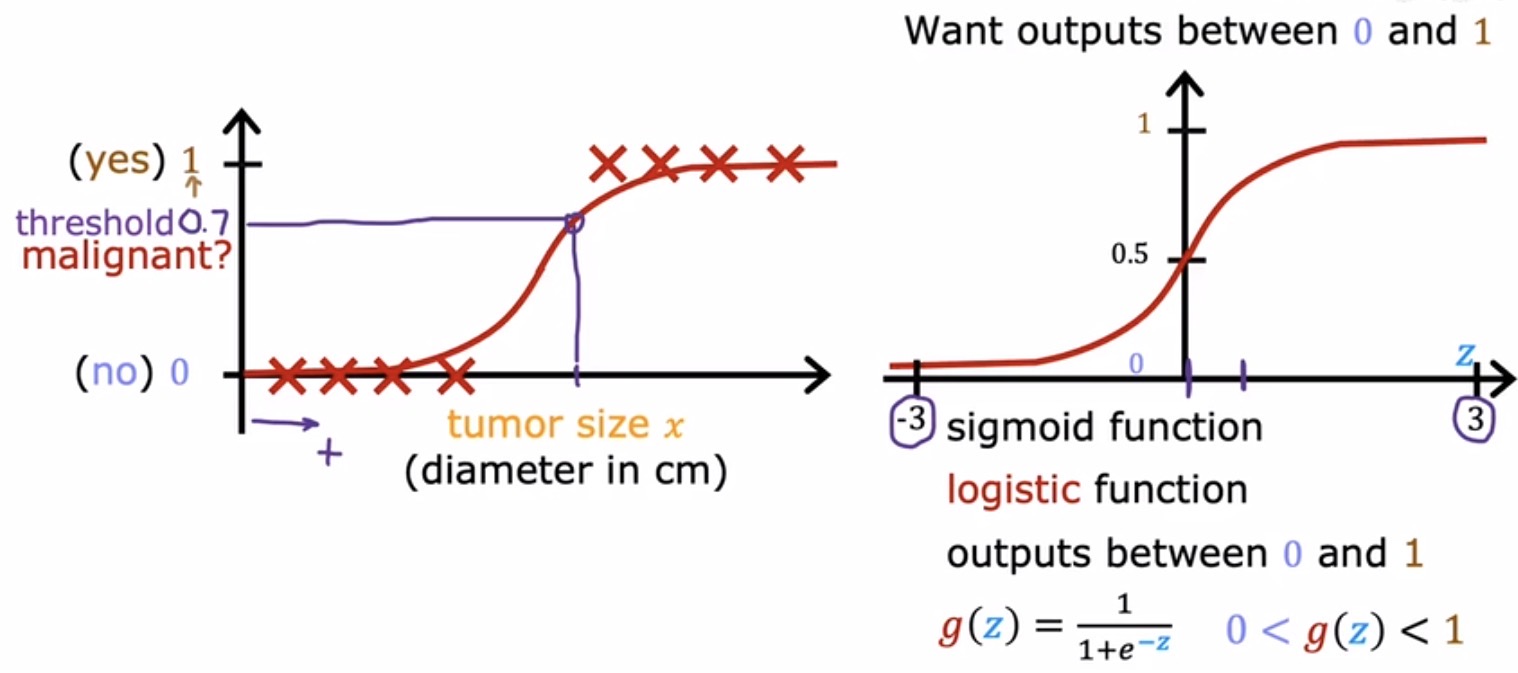
逻辑回归的做法,是将原先线性回归的输出 $\vec{w} \cdot \vec{x} + b$ 作为 $z$,送入 Sigmoid 函数中,从而将整个模型的输出值强行限制在 0 到 1 之间:
$$ f_{\vec{w},b}(\vec{x}) = g(\vec{w} \cdot \vec{x} + b) = \frac{1}{1 + e^{-(\vec{w} \cdot \vec{x} + b)}} $$
这个输出值可以被赋予概率含义:给定输入特征 $\vec{x}$ 和参数 $\vec{w}, b$,模型预测 $y=1$ 的概率就是 $f_{\vec{w},b}(\vec{x})$。相应地,$y=0$ 的概率则为 $1 - f_{\vec{w},b}(\vec{x})$。
决策边界:模型如何划定分界线
有了概率输出,还需要一个规则将其转化为最终的类别标签。最自然的做法是以 0.5 为阈值:若 $f_{\vec{w},b}(\vec{x}) \ge 0.5$,预测为类别 1;否则预测为类别 0。观察 Sigmoid 函数可知,$g(z) \ge 0.5$ 当且仅当 $z \ge 0$。因此,决策规则可以等价地表述为:若 $\vec{w} \cdot \vec{x} + b \ge 0$,则 $\hat{y} = 1$;若 $\vec{w} \cdot \vec{x} + b < 0$,则 $\hat{y} = 0$。
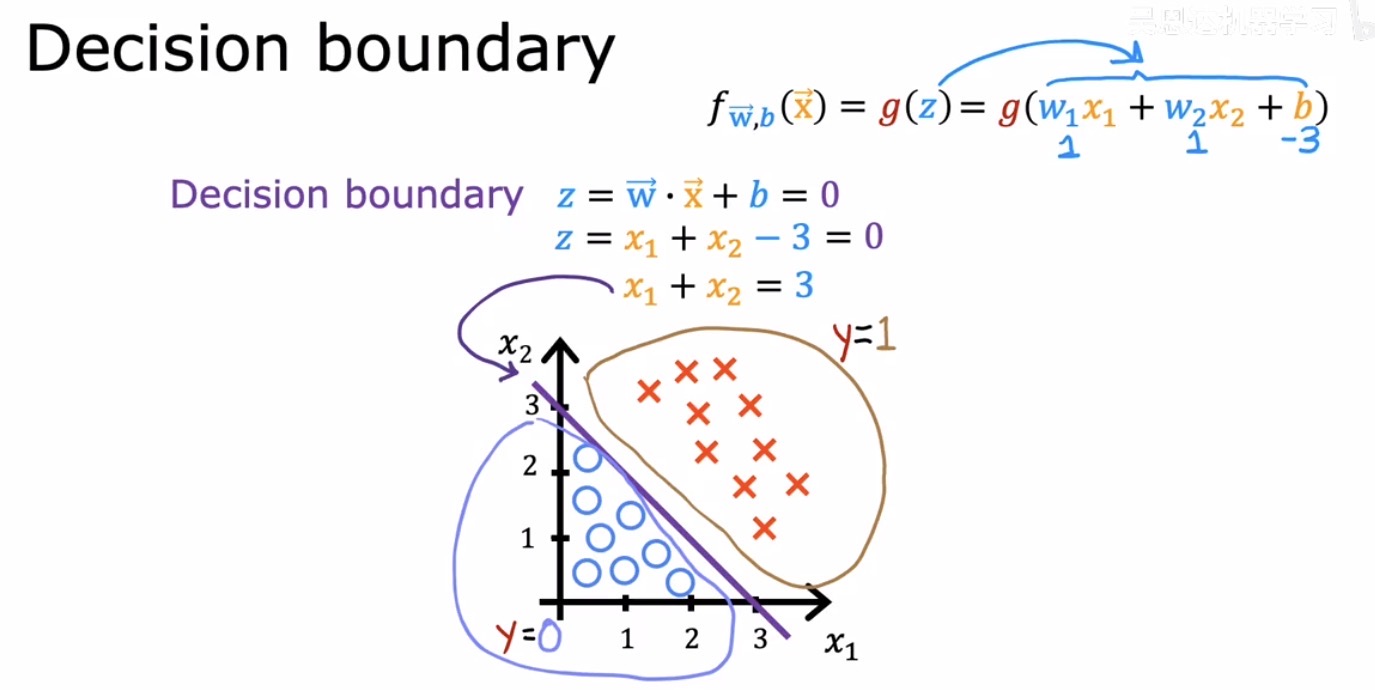
方程 $\vec{w} \cdot \vec{x} + b = 0$ 定义了一个在特征空间中的几何曲面,它将整个空间一分为二,一侧对应类别 1 的预测,另一侧对应类别 0。这个分界面就是决策边界(Decision Boundary)。
来看一个具体的二维特征例子。设模型为 $f_{\vec{w},b}(\vec{x}) = g(x_1 + x_2 - 3)$。对应的决策边界方程为 $x_1 + x_2 - 3 = 0$,即 $x_2 = -x_1 + 3$。这是一条斜率为 -1、截距为 3 的直线。落在直线右上方的点满足 $x_1 + x_2 > 3$,预测为 1;左下方的点预测为 0。
逻辑回归的能力远不止画出笔直的分界线。通过特征工程引入多项式项,可以构造出千变万化的非线性决策边界。例如,在模型中添加平方项:$z = x_1^2 + x_2^2 - 1$。令 $z=0$ 得到 $x_1^2 + x_2^2 = 1$,这是一个圆心在原点、半径为 1 的单位圆。模型将以这个圆为界,将特征空间划分为圆内和圆外两个区域。

引入更高阶的多项式或更复杂的交互项,决策边界可以呈现出椭圆、双曲线甚至任意奇特的形状,为分类问题提供了极强的灵活性。
逻辑回归的代价函数:告别均方误差
模型结构已定,接下来的问题是如何衡量模型预测与真实标签之间的差距,即如何定义代价函数。一个自然的念头是继续沿用线性回归中表现良好的均方误差。然而,当将 Sigmoid 函数的输出代入均方误差公式后,得到的代价函数关于参数 $\vec{w}, b$ 的图像会变得异常崎岖,布满大量局部极小值,呈现出极度非凸的形态。
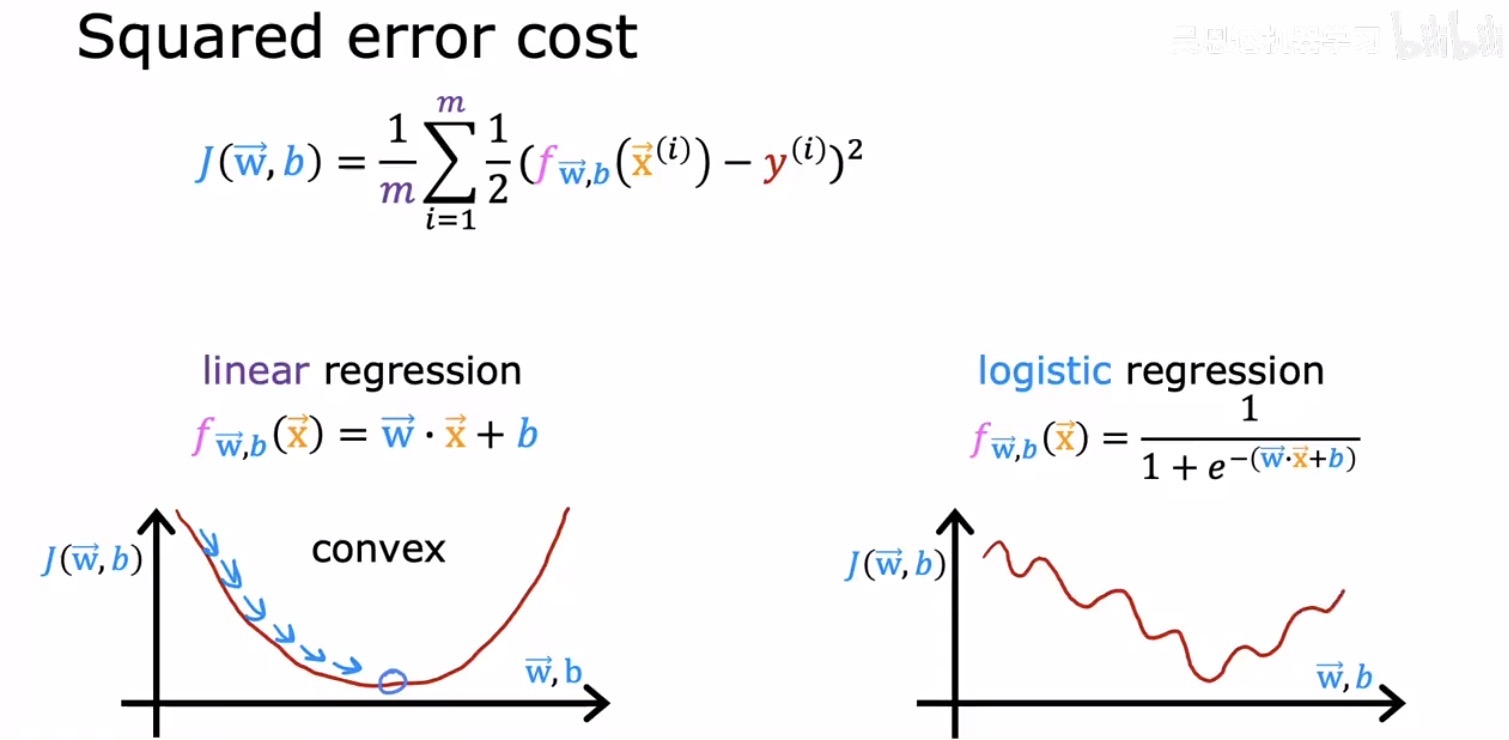
在这样的曲面上,梯度下降极易陷入某个次优的局部低谷而无法抵达全局最优解,这对模型性能是毁灭性的打击。因此,逻辑回归必须设计一个专门的、保证为凸函数的代价函数。
这个代价函数的推导源自统计学中的最大似然估计原理,并非凭空捏造。首先定义一个用于衡量单个样本预测表现的损失函数 $L$。鉴于标签 $y$ 只有 0 和 1 两种可能,损失函数也需要分情况定义:
- 当真实标签 $y=1$ 时,损失为 $L = -\log(f_{\vec{w},b}(\vec{x}))$。此时若模型预测的概率 $f$ 接近 1,则损失趋近于 0;若预测概率 $f$ 接近 0,则损失趋向正无穷,给予模型严厉的惩罚。
- 当真实标签 $y=0$ 时,损失为 $L = -\log(1 - f_{\vec{w},b}(\vec{x}))$。若预测概率 $f$ 接近 0(即正确预测为类别 0),损失趋近于 0;若预测概率 $f$ 接近 1(即错误地预测为类别 1),损失趋向正无穷。
这两个分段函数可以利用 $y$ 只能取 0 或 1 的特性,巧妙地合并成一个紧凑的表达式:
$$ L(f_{\vec{w},b}(\vec{x}), y) = -y \log(f_{\vec{w},b}(\vec{x})) - (1-y) \log(1 - f_{\vec{w},b}(\vec{x})) $$
当 $y=1$ 时,第二项 $(1-1)\log(\dots)$ 为零,表达式退化为第一种情况;当 $y=0$ 时,第一项 $-0 \cdot \log(\dots)$ 为零,表达式退化为第二种情况。
整个训练集上的代价函数 $J(\vec{w},b)$ 是所有样本损失的平均值:
$$ J(\vec{w},b) = \frac{1}{m} \sum_{i=1}^{m} L(f_{\vec{w},b}(\vec{x}^{(i)}), y^{(i)}) $$
这个代价函数是参数的凸函数,因而可以放心地使用梯度下降进行优化。对其求偏导的过程虽然稍显繁复,但最终结果的形式却异常简洁,与线性回归的梯度公式在表面上几乎如出一辙:
$$ \frac{\partial J}{\partial w_j} = \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} $$ $$ \frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) $$
唯一的区别在于 $f_{\vec{w},b}(\vec{x})$ 的定义不同——线性回归中是线性函数,逻辑回归中是 Sigmoid 函数。将这两个偏导数嵌入梯度下降的更新框架中,逻辑回归便能顺利训练,找到使代价函数最小的参数组合。
过拟合与正则化:在欠佳与过火之间寻求平衡
偏差与方差的权衡
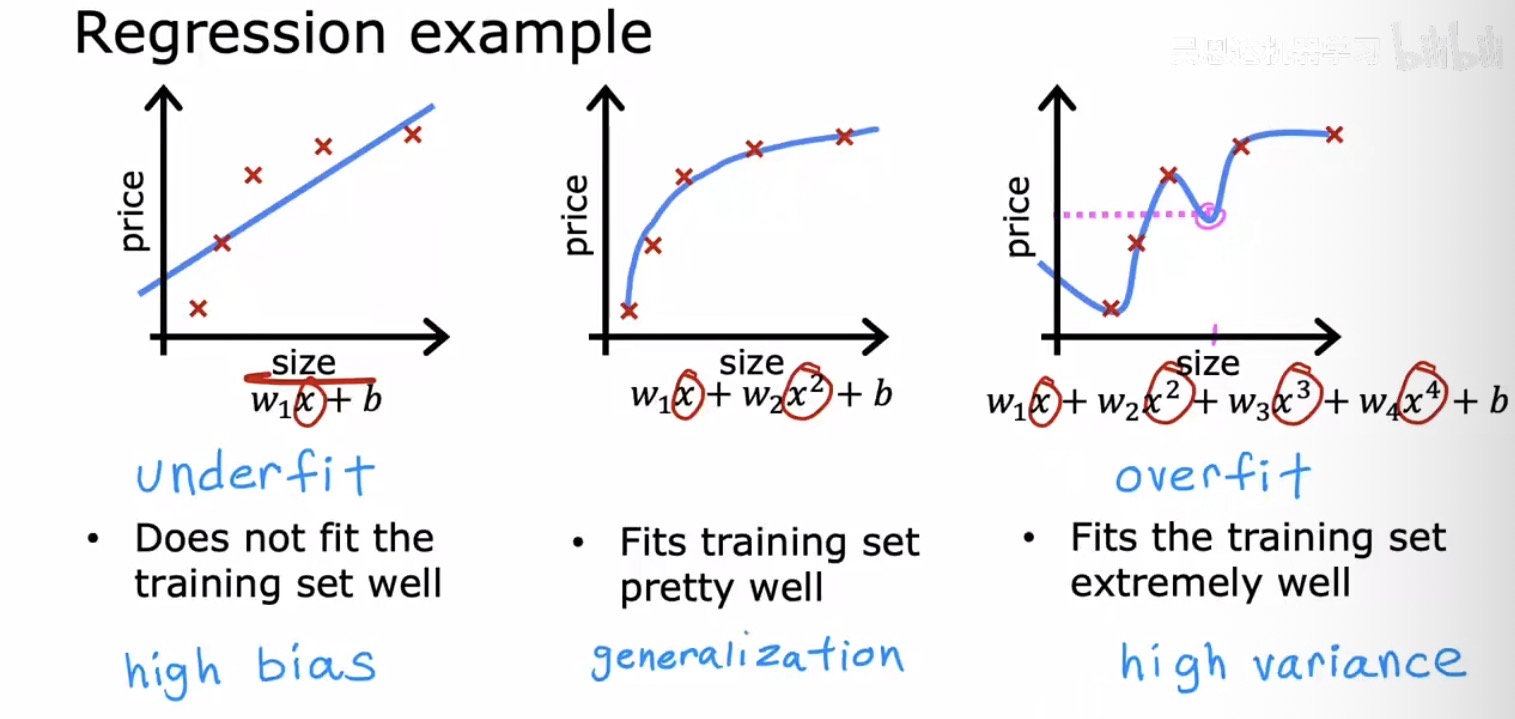
训练一个机器学习模型时,最希望看到的结果是它不仅能在训练数据上表现良好,更要在未曾见过的全新数据上同样做出准确预测。这种举一反三的能力被称为泛化(Generalization)。然而,模型的复杂程度与实际问题的匹配度,决定了泛化能力的强弱。
如果模型过于简单,预设了过于强烈的偏见,比如非要用一条直线去拟合一个本质上是曲线的数据分布,那么无论怎样训练,模型都无法捕捉到数据中的真实规律。这种情况称为欠拟合(Underfitting),也称高偏差(High Bias)——模型对数据的假设偏差过大,导致连训练集都拟合不好。
反过来,若模型过于复杂,比如用一个十次多项式去拟合仅有寥寥几个散点的数据,模型会将每一个训练样本——包括那些由随机噪声引起的微小波动——都一丝不苟地记住并拟合出来。这样的模型在训练集上看似完美无瑕,误差接近于零,但一旦面对新数据,那些被过度放大的噪声拟合就会成为沉重的包袱,导致预测表现一落千丈。这称为过拟合(Overfitting),也称高方差(High Variance)——模型对训练数据的细微变化过于敏感,缺乏稳定性。
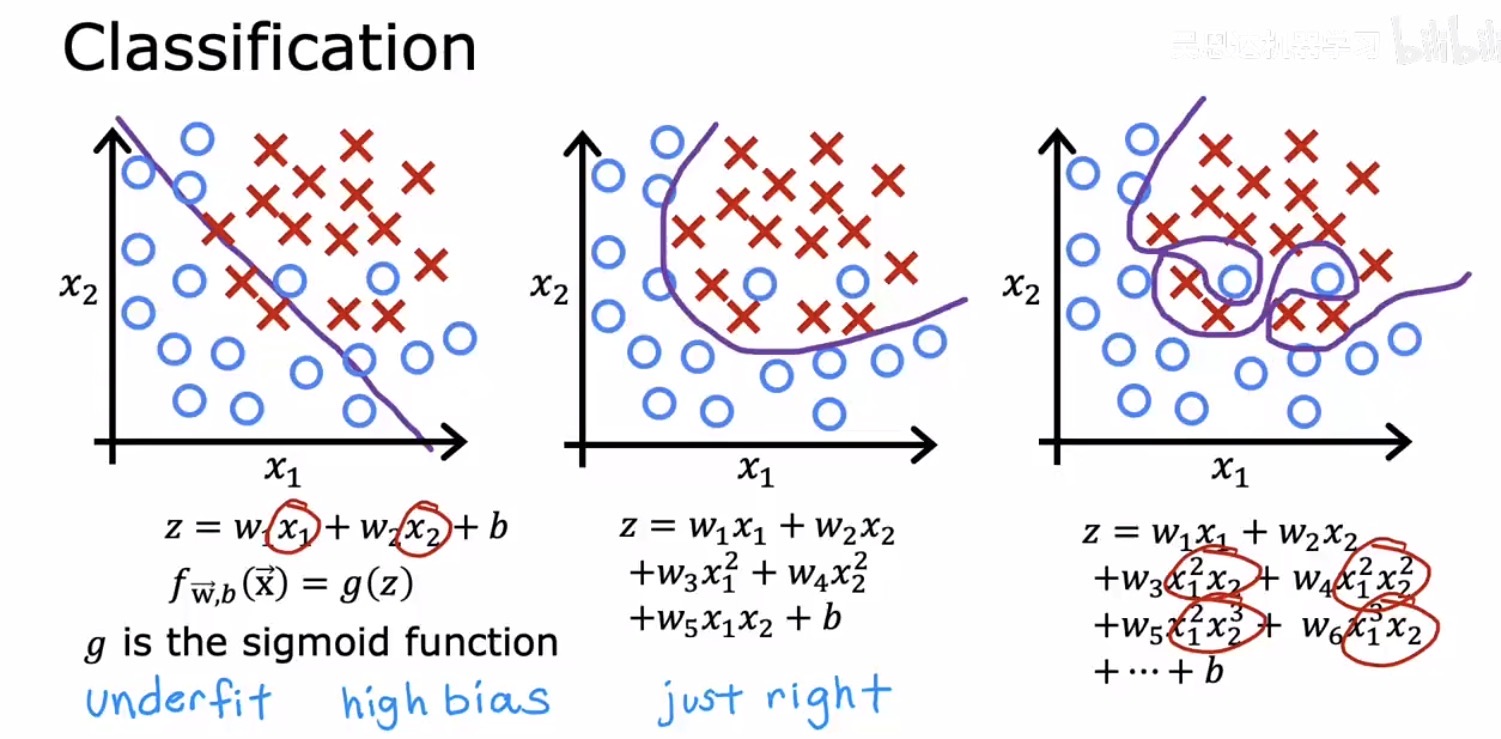
分类任务中同样存在这三种状态。左图欠拟合的决策边界过于简单,无法有效分隔两类样本;中图恰如其分地捕捉到了数据的大致轮廓;右图过拟合的决策边界则为了迁就个别样本点而变得诡谲扭曲,极不自然。
应对过拟合的策略
面对过拟合,有几种行之有效的应对思路。
第一种是收集更多的训练数据。数据量越大,模型就越难去“死记硬背”每一个孤立的样本,从而被迫去学习数据背后真正具有普适性的宏观规律。但获取额外数据往往代价高昂甚至不太现实,因此这一方法虽好,适用场景却有限。
第二种是进行特征选择。从所有可用特征中,依据领域知识或统计指标挑选出最具有代表性和解释力的一个子集,舍弃那些冗余或噪声过大的特征。这样做的代价是可能丢失一部分有用的信息,且特征选择本身也是一个需要精心设计的环节。
第三种方法最为优雅,它既不要求新增数据,也不要求删减特征,而是在不减少信息输入的前提下,通过对模型参数施加约束来抑制过拟合——这就是正则化(Regularization)。
正则化的思想与代价函数修正
正则化的核心直觉是:过拟合往往伴随着某些特征对应的权重参数 $w_j$ 绝对值变得异常巨大。一个高次多项式之所以能弯弯绕绕穿过每一个数据点,正是因为那些高阶项的系数被训练到了很大的数值,使得曲线在局部剧烈震荡。
因此,如果能在优化目标中,除了要求模型在训练数据上误差小之外,还额外增加一项对参数大小的惩罚,就能迫使算法在追求低误差的同时,还要尽可能保持参数数值的紧凑与克制。将这一惩罚项直接附加在原代价函数之后,便得到了正则化代价函数。
以线性回归为例,正则化后的代价函数形式如下:
$$ J(\vec{w},b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right)^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 $$
新加入的项 $\frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2$ 称为正则化项(Regularization Term)。其中的 $\lambda$ 是一个需要手动设定的超参数,名为正则化参数,它控制着惩罚力度的强弱。注意正则化项中只对权重 $w_j$ 进行约束,偏置项 $b$ 一般不参与正则化,因为 $b$ 仅影响模型的整体平移,不改变模型的复杂度和震荡程度。
$\lambda$ 的取值直接决定了模型最终的拟合倾向。若 $\lambda = 0$,惩罚项消失,退化为原始的无正则化模型,有过拟合风险。若 $\lambda$ 取得过大,算法会将绝大部分精力放在压缩 $w_j$ 的数值上,以至于所有 $w_j$ 都趋近于零,模型 $f_{\vec{w},b}(\vec{x}) \approx b$ 几乎变成一条水平线,反而陷入了欠拟合的泥潭。因此,$\lambda$ 需要在偏差与方差之间小心平衡,通常借助验证集上的表现来选取一个合适的值。
正则化下的梯度下降
将正则化代价函数代入梯度下降框架中,参数的更新公式也会发生相应的变化。对 $w_j$ 求偏导时,正则化项 $\frac{\lambda}{2m} w_j^2$ 的导数为 $\frac{\lambda}{m} w_j$。因此更新规则变为:
$$ w_j = w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} + \frac{\lambda}{m} w_j \right] $$
将含 $w_j$ 的项整理到一起:
$$ w_j = w_j \left(1 - \alpha \frac{\lambda}{m}\right) - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} $$
由于 $\alpha$、$\lambda$、$m$ 均为正数,系数 $\left(1 - \alpha \frac{\lambda}{m}\right)$ 是一个略小于 1 的数。这意味着在每一次梯度下降更新之前,$w_j$ 都会先被轻微地缩减一点点,然后再减去由数据误差驱动的梯度项。这种每一轮都略微“衰减”的机制,正是正则化抑制参数过度膨胀、防止过拟合的本质所在。偏置项 $b$ 的更新公式则维持原样,不引入额外衰减。
正则化逻辑回归
逻辑回归同样可以享受正则化带来的益处。其正则化代价函数只需在原逻辑回归代价函数的末尾加上相同的正则化项:
$$ J(\vec{w},b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\vec{w},b}(\vec{x}^{(i)})) + (1-y^{(i)}) \log(1 - f_{\vec{w},b}(\vec{x}^{(i)})) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 $$
梯度下降更新时,对 $w_j$ 的偏导数也会多出 $\frac{\lambda}{m} w_j$ 这一项,其余部分保持不变。由于逻辑回归中的 $f_{\vec{w},b}(\vec{x})$ 是 Sigmoid 函数,其导数形式更为复杂,但最终整理出的梯度表达式与线性回归在结构上惊人地相似,这也体现出梯度下降作为一种通用优化框架的普适之美。
通过正则化的约束,逻辑回归的决策边界会变得更加平滑、更具普适性,不再为了迁就个别样本而画出乖张怪异的曲线,模型的泛化能力因此得到显著提升。
